This week I was in Canterbury leading a workshop and discussion on Google and Google Scholar for finding research information. Although the emphasis was on Google we also covered other specialist tools designed to search for scientific and research information. We also had an interesting discussion on h-index, other citation indices and services such as ORCID and ResearchGate. The slides for the session are available on authorSTREAM (http://www.authorstream.com/Presentation/karenblakeman-1706478-google-scholar-research-information/), Slideshare (http://www.slideshare.net/KarenBlakeman/scholar-research-information) and temporarily at http://www.rba.co.uk/as/.
Anyone who has attended one of my workshops knows that I ask the group to propose at the end of the session their top tips. These are the Canterbury group’s top 10 tips.
1. What’s going on?
Try and find out what’s going on behind the scenes and how the different search tools work. For example, Google and Google Scholar are quite different in the way they manage your search. Understanding how they operate means that you can adapt your search strategy accordingly and also manage your expectations; for example Google Scholar does not use the publishers’ meta data so author and date search are unreliable.
2. Personalisation and ‘unpersonalisation’
Google personalises your search based on past activity, who is in your social networks,and a whole host of other ‘stuff’. You can quickly ‘unpersonalise’ your results by using a separate browser window that does not use cookies or your web history as part of the search algorithm.
If you use Chrome as your browser, open what is called an incognito window. In the top right hand corner of your screen there is an icon with three lines. Click on it and from the drop down menu select New incognito window. Alternatively press the Ctrl Shift N keys on your keyboard
If you use Firefox, from the menu at the top of the screen select Tools followed by Start Private Browsing.
In Internet Explorer select Tools followed by InPrivate Browsing. If you cannot see InPrivate under Tools try looking under the Safety option.
3. Advanced search commands
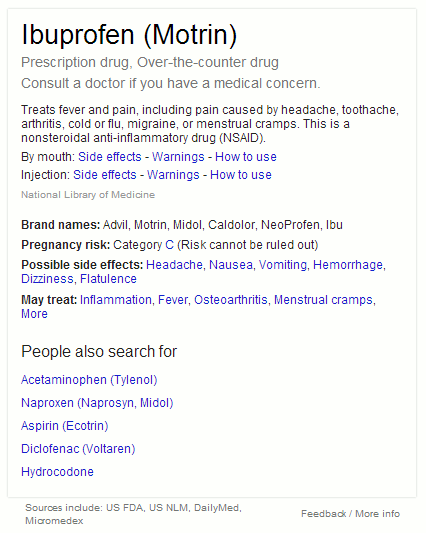
Use Google advanced commands such as filetype: to focus on PDFs, presentations, spreadsheets containing data and site: to look for information on just one site or a range of sites such as UK government. Although the advanced search screen has boxes for you to fill in for the commands the file format or filetype option is limited. It does not include options for the newer Microsoft Office formats such as .pptx and xlsx. Use filetype: as part of your search strategy, for example:
nasa dark energy dark matter filetype:pptx
Google Scholar commands are more limited – see slide 28 of the presentation.
4. intext:
Google automatically looks for variations on your terms and sometimes omits words from your search if it thinks the number of results is too low. Prefixing a term with intext: tells Google that it must be included in your search and exactly as you have typed it in. For example:
UK public transport intext:biodiesel statistics
tells Google that biodiesel must be included in the search and exactly as typed in.
5. Reading Level
Use Reading level if Google is failing to return any research oriented documents for a query. Run the search and from the menu above the results select Search tools, All results and then from the drop menu Reading level. Options for switching between basic, intermediate and advanced reading levels should then appear just above the results. Google does not give much away as to how it calculates the reading level and it has nothing to do with the reading age that publishers assign to publications. It seems to involve an analysis of sentence structure, the length of sentences, the length of the document and whether scientific or industry specific terminology appears in the page.
6. Date options
In Google web search, use the date options in the menus at the top of the results page to restrict your results to information that has been published within the last hour, day, week, month, year or your own date range. Click on Search tools, then Any time and select an option. This works best with news, discussion boards, and blogs and web sites that use blogging software to generate pages but Google is getting better at identifying the correct date of a web page.
Google Scholar handles publication dates differently. On the results page you can select a date range from the menu on the left hand of the page. Alternatively, you can run a Google advanced search and enter your publication years. However, Google Scholar looks for publication years in the area of the document where the date is most likely to be. As a result it may identify a page number or part of an author’s address as a year!
7. Google Scholar alerts
To be used with caution as the searches periodically stop without warning, and so have to be set up again, and they sometimes include documents that are several years old. Whatever your search you can set up an alert by selecting Create alert from the menu on the left hand side of the results page.
If the author has created a profile on Google Scholar, from their profile page you can follow new articles and/or new citations for that author. From past experience I warn you that this is not entirely reliable.

8. Metrics – top publications
Although it claims to search all scholarly literature Google Scholar does not always cover all of the key journals in a subject area. There is no complete source list but there is a top publications for subjects and languages under the ‘Metrics’ link in the upper right hand corner of the Scholar home page.
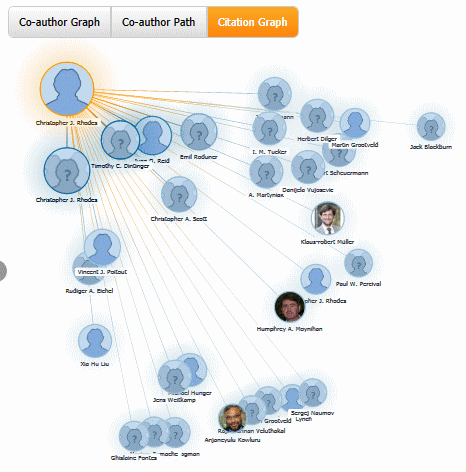
9. Microsoft Academic Search – visualisations
Microsoft Academic Search (http://academic.research.microsoft.com/) is a direct competitor to Google Scholar. The site is sometimes slow to load and it often assigns authors to the wrong institution. Nevertheless, the visualisations such as the co-author and citation maps can be useful in identifying who else is working in a particular area of research. The visualisations can be accessed by clicking on the Citation Graph image to the left of the search results or author profile.
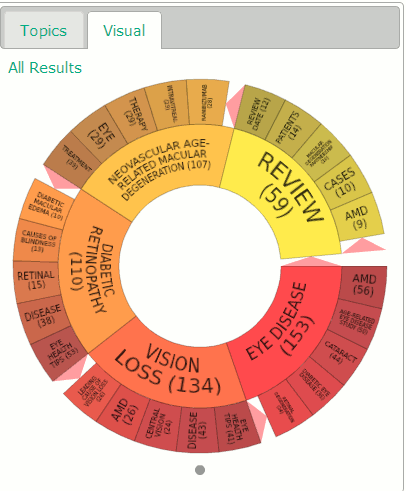
10. Mednar visual
Deep Web Technologies has developed in conjunction with various institutions a number of science and research specific portals, some of which are publicly available. The sources that they cover are different but they all have similar search and display options. Results are automatically ranked by relevance but this can be changed to date, title or author. In addition to the standard relevance ranked list of results the portals create clusters of topics on the left hand side of the screen. The topics include broad subject headings, authors, publications, publishers, and year of publication and are a useful tool for narrowing down a search. Some of the portals, such as Mednar (http://mednar.com/), offer a clickable ‘visual’ of topics and sub-topics.