When running advanced search workshops, and especially Google sessions, I prefer not to dwell on commands and search options that are no longer supported. They are gone and that is that, and it is far better to concentrate on how to get the best out of what is left. Of course it is unavoidable when your slides have been prepared several days before the event and Google decides to pull the plug on one of your favourite search features just before you start! Similarly I tend not to show “this is how NOT to use….” a command or incorrect syntax. It is often the incorrect format that one remembers. Recently, though, I have added slides to my presentations that cover both defunct commands and errors in syntax and format.
The problem is that not only are many people unaware that some search options are no longer available but also some fact sheets and articles covering advanced search are getting it wrong. The recent Guardian article on top search tips for Google almost got it right but referred to the tilde, which was dropped in 2013, and did not really understand how Google automatically looks for synonyms and variations on a term (see my earlier blog posting Guardian’s top search tips for Google not quite tiptop). I have also seen a couple of recently produced Google fact sheets riddled with mistakes.
The wonderful thing about Google is that it can take the most tortuous and error ridden search string and still come back with something that is sensible – most of the time. The downside of this is that one assumes the search query has worked as intended when in fact Google has totally rewritten the search for you. At some point, though, Google will rewrite the search in such a way that it brings back rubbish. So, it is important to know what commands are available and how they should be used.
Let’s get started.
Plus (+) sign before a word to force an exact match.
This was discontinued in October 2011 because Google intended to use it as a way to search for Google+ pages. That has been abandoned and it is now a searchable character. If you want to force an exact match search on a term precede the term with intext: for example intext:agriculture.
I have also seen examples claiming that a plus sign between words acts as a Boolean AND. No, it doesn’t. If you do get different results when using + it is because Google is searching for that as well as your terms.
Tilde (~) for synonyms
This was withdrawn in June 2013 because not many people used it and it was no longer needed. Google now looks for synonyms by default.
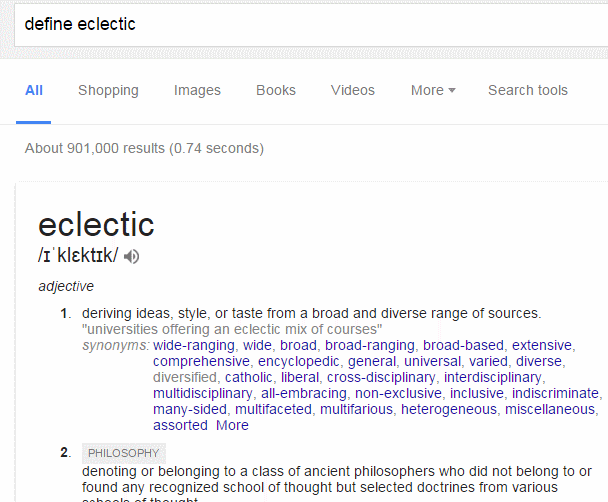
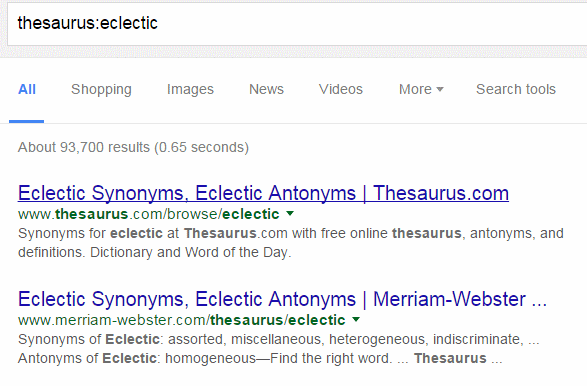
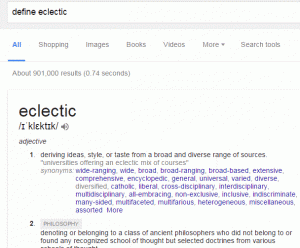
thesaurus: for alternative terms
‘thesaurus:’ sort of works because Google treats ‘thesaurus’, having ignored the colon, as a search term. So ‘thesaurus:eclectic’ will give you links to pages and websites of dictionaries and definitions that give synonyms for eclectic. It does not give you a straightforward list of alternatives in the same way that ‘define’ does. If you use thesaurus you have to go the websites in turn to view the synonyms.
The asterisk *
The asterisk (*) is a placeholder for terms between two words e.g. solar * panels finds solar photovoltaic panels, solar PV panels, solar thermal panels. It is NOT a truncation symbol. Again, you might think it is because Google ignores the asterisk and automatically looks for words that begin with the letters you have typed in.
The example I gave in my earlier blog posting was a search on phenobarb*. I expected Google to pick up references to phenobarbitone. It picked up 76,000 results including phenobarbital but there was no mention of phenobarbitone in the first 100. Phenobarb without the asterisk picked up the exact same results. A search on phenobarbitone, with and without the asterisk came up with 241,000 results. I have no idea how or when Google decides to stop looking for variations on your string but it is obvious from the above example that the asterisk is not a truncation symbol.
Do NOT capitalise the first letter of commands, and NO spaces
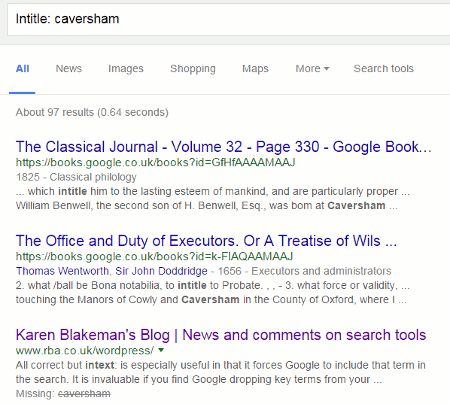
Commands such as intitle:, intext:, filetype: and site: must be all lower case and NO spaces between the colon and the search term. Capitalise the first letter or add a space after the colon or both and Google treats the command as an ordinary searchable word.
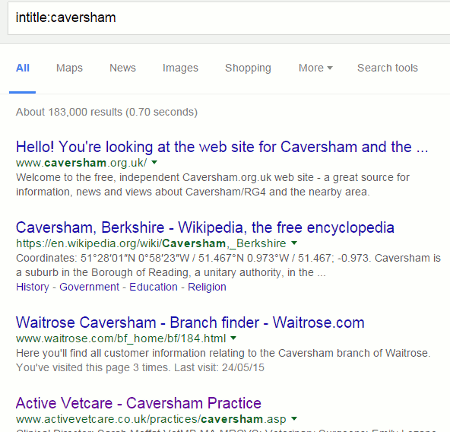
The correct format for an intitle: search is, for example, intitle:caversham and finds the following:
Capitalise the first letter of the command or insert a space or both and you find:
 I do understand why so many fact sheets, and presentations, show commands with an initial capital letter. You spend ages preparing your information and when you have sent off your slides for printing or converted your document to a PDF you discover that Microsoft Office has changed the format of the command. Because your search example is on a separate line with the command at the start Office, bless it, decides to auto-correct and capitalise the first letter. I know, it has happened to me! So, please, check and double check your support materials.
I do understand why so many fact sheets, and presentations, show commands with an initial capital letter. You spend ages preparing your information and when you have sent off your slides for printing or converted your document to a PDF you discover that Microsoft Office has changed the format of the command. Because your search example is on a separate line with the command at the start Office, bless it, decides to auto-correct and capitalise the first letter. I know, it has happened to me! So, please, check and double check your support materials.
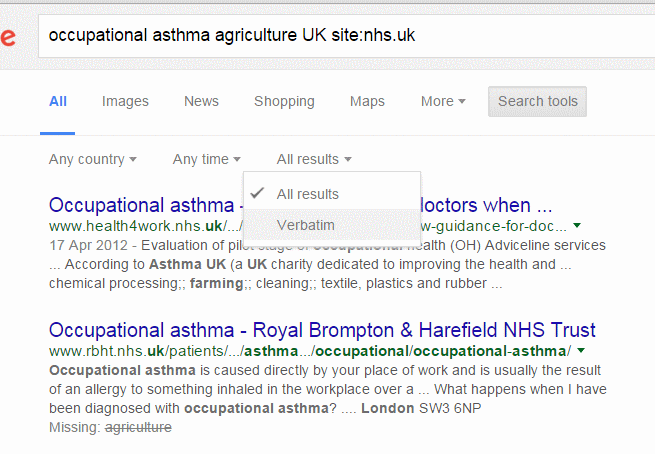
Google searches for all of your terms by default
Not always. If your search, as it stands, finds zero or a low number of results then Google will drop one or more terms that are usually shown as strikethroughs. In the above screenshot you can see that the third entry in the results has a “Missing: caversham” at the end of the snippet.
If Google is dropping a term that is essential to your search then prefix it with intext:, for example intext:caversham. If you want all of your terms to be included, and without any variations, then use the Verbatim search option. If you are using a desktop or laptop run your search and then click on the Search tools option at top of your results. A second line of options will appear. Click on All results and select Verbatim. The layout and location of Verbatim on mobile devices will usually be different.
Double quotation marks around phrases
Double quotation marks around phrases, titles of papers, song titles, famous sayings etc. works most of the time. But, again, if Google finds zero or only a handful of results it will ignore the marks. Google may also alter the spelling of one or more words within the double quotation marks. Use Verbatim if you are sure that the phrase is correct and you want to bring Google to heel.
Full nested Boolean search
Google has NEVER supported full nested Boolean search. I still meet people who are adamant that Google does, but when pushed they admit that they often get unexpected results. You can , though, use OR for alternative terms and the minus sign before a term to exclude documents containing that term.
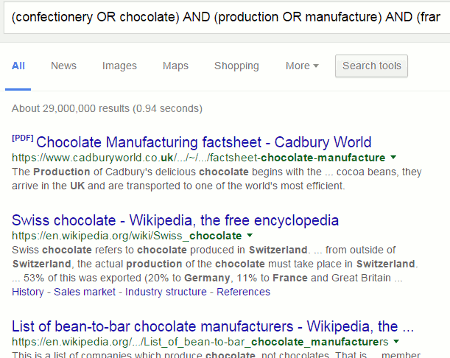
This is how Google interprets the search (confectionery OR chocolate) AND (production OR manufacture) AND (france OR Germany OR UK OR switzerland) NOT belgium
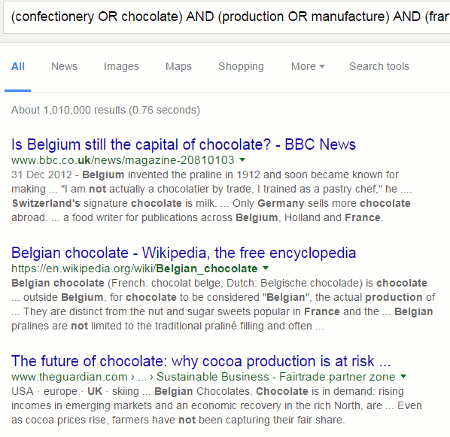
Note that pages containing Belgium are included rather than excluded.
Remove the ‘NOT Belgium’ and this is what we see:
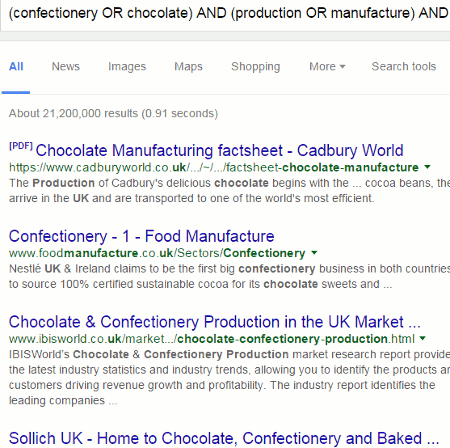
Add ‘-belgium’ to the end of the search instead of ‘NOT belgium’ and we get:
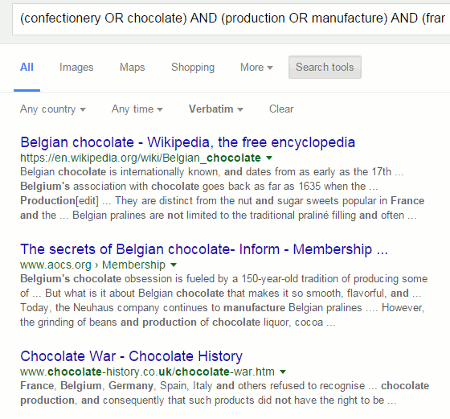
Running Verbatim on our original Boolean search shows that Google is treating AND and NOT as lower case, searchable words:
If you really want to use full Boolean, then get thee hence to Bing.
If you want to learn more about Google search Dan Russell, who works at Google, is currently running an online course on Power Searching with Google. Alternatively, if you want a more business or academic research and UK/European oriented workshop on what Google can do I am running an advanced Google workshop with UKeiG on April 13th, 2016.

 The ones at the top with the grey background are the tags that I assigned to the photo. The rest are Flickr’s.
The ones at the top with the grey background are the tags that I assigned to the photo. The rest are Flickr’s.