I have worked in the information profession for over twenty years and have been a freelance consultant since 1989. My company (RBA Information Services) provides training and consultancy on the use of the Internet, and on accessing and managing information resources. Prior to setting up RBA I worked at the Colindale Central Public Health Laboratory, and then spent ten years in the Pharmaceutical and Health Care industry before moving to the International management consultancy group Strategic Planning Associates.
I edit and publish an electronic newsletter called Tales from the Terminal Room. Other publications include Search Strategies for the Internet.
I am a Fellow of CILIP: The Chartered Institute of Library and Information Professionals, a member of the UK eInformation Group (UKeiG).
The slides from my talk at the Anybook Oxford Libraries Conference in July 2015 are now available on Slideshare via the Bodleian Staff Development account.
As well as advanced Google search features and alternative search tools I comment on the direction Google is going in. Note that this presentation was given before the Alphabet announcement. Those of you who have attended my Google and non-Google search tool workshops should know most of what is in the slides, but they might serve as a useful reminder.
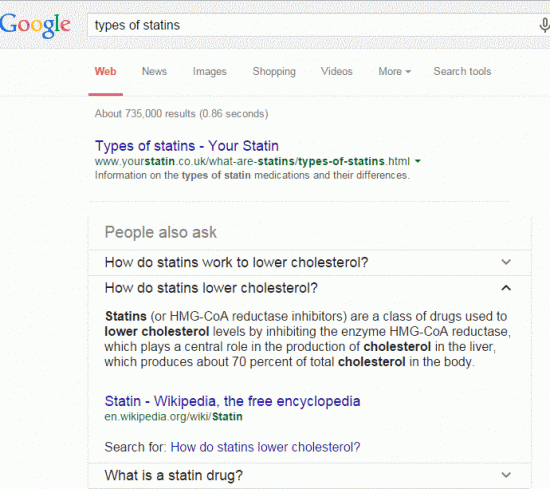
There have been reports (http://searchengineland.com/google-tests-new-mobile-search-design-people-also-ask-box-219078) for several months that Google has been testing a new query refinement box called “People also ask”. It now looks as though it has gone live. The feature suggests queries related to your search after the first few entries in your results list. It doesn’t appear for all queries and it is dependent on how you ask the question. My search on ‘what are statins’ gave me the usual, standard results list. When I searched on ‘types of statins’ the ‘People also ask’ box popped up with “How do statins work to lower cholesterol?”, “How do statins lower cholesterol?” and “What is a statin drug?
To see further information you have to click on the downward pointing arrow next to the query but instead of a list of sites you see just an extract from a page supposedly answering the question, a bit like the Quick Answers that sometimes appear at the top of your search results. There is an option, though, to run a full search on the query you have chosen. As with the Quick Answers, there are no clues as to how or why Google has selected a particular page to answer the query.
The queries for ‘People also ask’ are also different from the suggested queries that are listed as you type in your question into the standard Google search box.
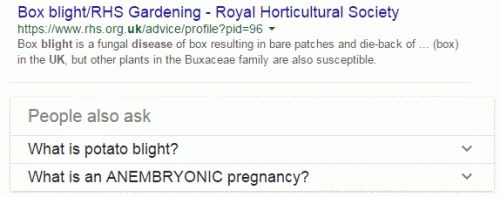
Those of you who have attended my talks and workshops will no doubt be waiting for me to come up with an example of a Google howler. Here it is: a search on ‘tomato blight prevention uk’ comes up with “What is potato blight?” (close, and the organism that causes late potato and tomato blight is the same) and “What is an ANEMBRYONIC pregnancy?”.
No, I don’t know what an ANEMBRYONIC pregnancy is (why the capital letters?) but it has nothing to do with potato or tomato blight!
At present, this is not a feature that I am finding useful. For me it is a hindrance rather than a help and just clutters up the results page with superficial or irrelevant suggestions. But as my queries tend to be quite complex and often incorporate advanced search commands, which seem to disable it, I don’t expect to be seeing much of this feature.
As well as the general dumbing down and relentless removal of search options, it covers the new technologies that Google is experimenting with: artificial intelligence, driver-less cars, robotics, home environment sensors and controls. Some of this is already being integrated with search and “mobile”.
I am running a “New Google, New Challenges” workshop for UKeiG this autumn in Manchester and London. It concentrates on search, how the changes at Google are impacting the way it manages our search and presents results, and how to use what is left of the advanced search techniques and specialist databases for more relevant research results.
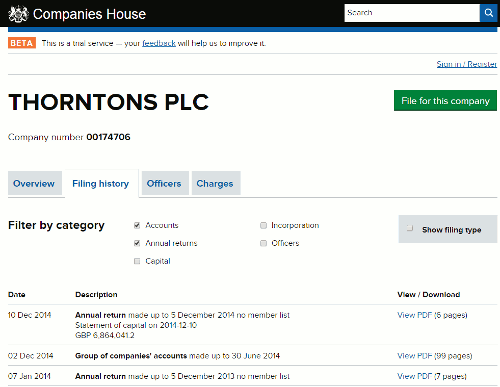
A year ago Companies House announced that they were going to make all of their company information available free of charge to everyone. The press release was short on detail and many of us wondered what format the data would be in and how easy it would be to use. Daily files containing accounts data registered on the previous day were already available but these are huge zip files that, when unpacked, contain files with meaningless names. (http://download.companieshouse.gov.uk/en_accountsdata.html). Unless you have software that can manage and search the data it is impossible to identify which files contain information on the company you are researching.
For most of us the files are useless. Was this to be the format of the free service? Thankfully, no.
A new beta service at http://beta.companieshouse.gov.uk/ now enables you to search for companies by name or number and obtain free of charge:
Company overviews
Current and resigned officers
Document images
Mortgage charge data
Previous company names
Insolvency data
For the officers you can see what other companies they are involved with. What you cannot do at the moment is search by director name from the start. That is a “planned feature” as are disqualified directors search, company monitoring, company name availability, dissolved companies and overseas data. For those options you have to revert to the old WebCHeck service at http://wck2.companieshouse.gov.uk/.
The new beta service is easy to use and at last we have access to UK company documents and accounts free of charge. So, does this mean the end of services such as Company Check (http://companycheck.co.uk/) and DueDil (http://www.duedil.com/)? Not necessarily. Company Check, for example, already has an option for searching by director name and there are also useful charting, monitoring and structure options as well as access to some European companies. They also offer access to risk scores, credit reports and County Court Judgments (all priced). All of these services only allow you to search for companies one at a time: there is no multi-criteria search that you can use to find companies by turnover, number of employees, industry sector for example. Neither can you compare companies or conduct a detailed peer group analysis. For that you still have to use priced services such as BvD (http://www.bvdinfo.com/)
Overall, a move in the right direction and ideal if your needs are simple, for example accounts and director information for a live company. But look carefully at what features are available before you cancel your subscription service.
I am running my full day business information, sources and search techniques workshop for the Commercial, Legal and Scientific Information Group (CLSIG).
Date: Thursday, 16 July 2015, 9:30am to 4:30pm
Venue: CILIP, 7 Ridgmount Street, WC1E 7AE London . See map: Google Maps
Cost: CLSIG/CILIP Members £85; Non-members £100; Concessions £50
Search engines, government and official information sources, and the EU regulatory environment are continually changing. All of these affect how we search and the information that is presented to us. In some cases information may be deliberately excluded from our results. This one day workshop will look at what’s new, key resources for business and official information, and how to use search tools to ensure you are picking up everything that you need. There will be time for practical sessions so that you can try some of the exercises provided, or experiment with your own searches. Lunch and refreshments are included.
Topics covered include:
effect of EU legislation on research and due diligence
increase in official open data – accessibility, quality, usability
changes to Google and other search tools, and their impact on research
starting points, evaluated listings and government sources
company information: official sources; free open data sources worldwide; companies that repackage official company information – pros and cons
news sources and alerting services
the value of social media and professional networks for business intelligence
My “abstract” cat (or possibly dog), according to Flickr
A few days ago Flickr revamped its website yet again. Flickr users have become used to changes that offer no improvements in functionality, and it rarely comes as a surprise that some aspects of the service are sometimes made worse. The most recent updates did not seem to be that significant. The layout is different; search is just as bad as ever with odd and irrelevant results popping up; and you still cannot directly edit an incorrectly, Flickr assigned location. The last is possible but it involves a somewhat Heath Robinson approach, more of which in a separate posting.
This time, though, Flickr has made a huge mistake. It has been using image recognition technology for about a year to automatically generate tags for users’ photos but, until now, those tags have been hidden from users. They are now visible. The official announcement is on the Help Forum, Updates on tags (http://www.flickr.com/help/forum/en-us/72157652019487118/) followed by many pages of users comments, mostly negative. Flickr’s mistake is not in making the tags visible or doing the tagging at all, but in not allowing users the option to opt-out or offering a global tag deletion tool.
The computer generated tags have been added retrospectively to everyone’s photos, so some of us now have the prospect of checking thousands of images for incorrect or irrelevant tags. My experience, so far, is that most of them are useless. I honestly cannot see how the tags “indoor” or “outdoor”, which seem to be applied to the majority of my photos, are helpful in a search. If the auto generated tags have already been used in Flickr’s search it would explain why the results are often rubbish.
It is easy to spot the difference between user and Flickr generated tags: the former are in a grey box and the latter in a white or light grey box.
Flickr user and automatically generated tags
If you want to delete a Flickr generated tag you have to do it tag by tag, photo by photo. Do not go on a tag deletion frenzy just yet, though. There are reports that the deleted tags sometimes reappear.
Oddities that I have spotted so far in my own photostream include a photo of our local polling station auto-tagged with “shop” (http://www.flickr.com/photos/rbainfo/17209179077/), and an image of a building site tagged with “snow” (http://www.flickr.com/photos/rbainfo/17332657995/). I suspect that in the latter case Flickr was confused by the amount of dust and debris surrounding what remains of the buildings.
To see the full horror of what Flickr has done, click on the Camera Roll link on your Photostream page and then Magic View. My cat has been tagged several times as a dog and once as abstract, which I suggest should be replaced by “Zen”. And to a photo of three hippos in Prague Zoo have been added animal, ape, elephant, tortoise, baby, child and people (http://www.flickr.com/photos/rbainfo/8712618469/). Note that Magic View only uses Flickr auto generated tags; we users are obviously not to be trusted!
I admit that there are a handful of instances where Flickr has reminded me of potentially relevant tags, so I might be tempted by an option whereby Flickr suggests additional tags. But I want to make the final decision as to whether to add them or not. I most certainly do not want Flickr adding, without my permission, thousands of tags to my back catalogue. And by the way, Flickr, whatever happened to my privacy setting of who can “Add notes, tags, and people:Only you”, which you have clearly breached.
It is bad enough to have to deal with the rubbish that Google dishes out, but to have to cope with Flickr’s lunacy as well is too much. Flickr, you have seriously messed up this time. Many of us do know what we are doing most of the time when we tag our photos. Carry on down this route and you won’t just annoy your users but risk losing a substantial number of them, some of whom pay for Pro accounts.
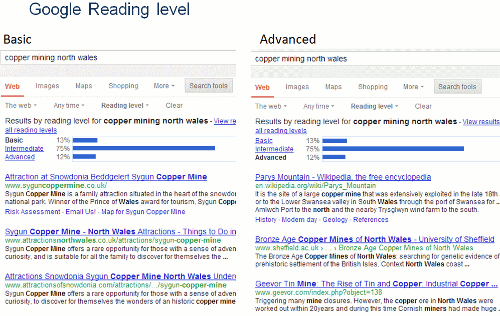
It seems that Google has dumped the Reading Level search filter. This was not one that I used regularly but it was very useful when I wanted more serious, in-depth, research or technically biased articles rather than consumer or retail focused pages. It often featured in the Top Tips suggested by participants of my advanced Google workshops.
It was not easy to find. To use it you had to first run your search and then from the menu above the results select ‘Search tools’, then ‘All results’, and from the drop menu ‘Reading level’. Options for switching between basic, intermediate and advanced reading levels then appeared just above the results.
Slide showing Google Reading Levels from one my search workshops
So another tool that helped serious researchers find relevant material bites the dust. I daren’t say what I suspect might be next but, if I’m right, its disappearance could make Google unusable for research.
“The quality of web sources has been traditionally evaluated using exogenous signals such as the hyperlink structure of the graph. We propose a new approach that relies on endogenous signals, namely, the correctness of factual information provided by the source. A source that has few false facts is considered to be trustworthy. The facts are automatically extracted from each source by information extraction methods commonly used to construct knowledge bases. We propose a way to distinguish errors made in the extraction process from factual errors in the web source per se, by using joint inference in a novel multi-layer probabilistic model. We call the trustworthiness score we computed Knowledge-Based Trust (KBT). On synthetic data, we show that our method can reliably compute the true trustworthiness levels of the sources. We then apply it to a database of 2.8B facts extracted from the web, and thereby estimate the trustworthiness of 119M webpages. Manual evaluation of a subset of the results confirms the effectiveness of the method.”
If this is implemented in some way, and based on Google’s track record so far, I dread to think how much more time we shall have to spend on assessing each and every source that appears in our results. It implies that if enough people repeat something on the web it will deemed to be true and trustworthy, and that pages containing contradictory information may fall down in the rankings. The former is of concern because it is so easy to spread and duplicate mis-information throughout the web and social media. The latter is of concern because a good scientific review on a topic will present all points of view and inevitably contain multiple examples of contradictory information. How will Google allow for that?
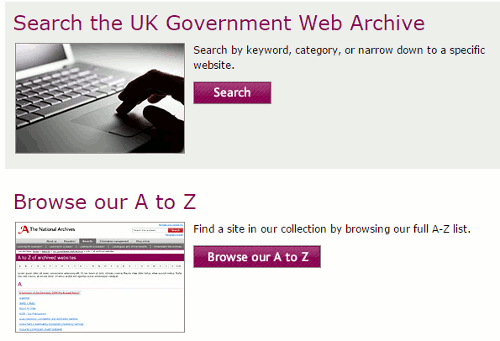
Documents may no longer be directly accessible from the new departmental home pages so a different approach is needed if you are conducting in-depth research. GOV.UK is fine for finding out how to renew your car tax or book your driving theory test – two of the most popular searches at the moment – but its search engine is woefully inadequate when it comes to locating detailed technical reports or background papers. Using Google’s or Bing’s site command to search GOV.UK is the only way to track them down quickly, for example biofuels public transport site:www.gov.uk. Note that you need to include the ‘www’ in the site command as site:gov.uk would also pick up articles published on local government websites. This assumes, though, that the document you are seeking has been transferred over to GOV.UK.
There have been complaints from researchers, including myself, that an increasing number of valuable documents and research papers have gone AWOL as more departments and agencies are assimilated Borg-like by GOV.UK. Some of the older material has been moved to the UK Government Web Archive at http://www.nationalarchives.gov.uk/webarchive/.
This offers you various options including an A-Z of topics and departments and a search by keyword, category or website. The latter is slow and clunky with a tendency to keel over when presented with complex queries. I have spent hours attempting to refine my search and wading through page after page of results only to find that the article I need is not there, nor anywhere else, which is an experience several of my colleagues have had. This has led to conspiracy theories suggesting that the move to GOV.UK has provided a golden opportunity to “lose” documents.
I am reminded of a scene from Yes Minister:
James Hacker: [reads memo] This file contains the complete set of papers, except for a number of secret documents, a few others which are part of still active files, some correspondence lost in the floods of 1967…
James Hacker: Was 1967 a particularly bad winter?
Sir Humphrey Appleby: No, a marvellous winter. We lost no end of embarrassing files.
James Hacker: [reads] Some records which went astray in the move to London and others when the War Office was incorporated in the Ministry of Defence, and the normal withdrawal of papers whose publication could give grounds for an action for libel or breach of confidence or cause embarrassment to friendly governments.
James Hacker: That’s pretty comprehensive. How many does that normally leave for them to look at?
James Hacker: How many does it actually leave? About a hundred?… Fifty?… Ten?… Five?… Four?… Three?… Two?… One?… *Zero?*
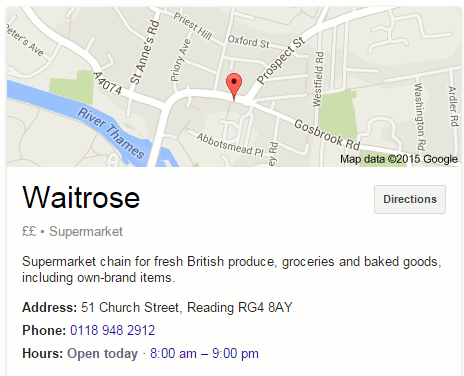
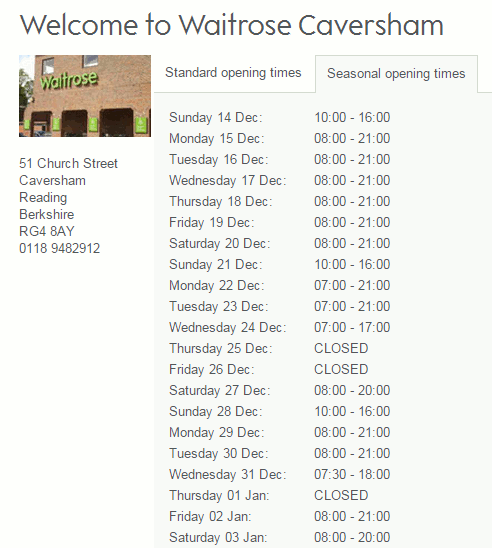
Yesterday, on New Year’s Day, I came across yet another example of Google getting its Knowledge Graph wrong. I wanted to double check which local shops were open and the first one on the list was Waitrose. I vaguely recalled seeing somewhere that the supermarket would be closed on January 1st but a Google search on waitrose opening hours caversham suggested otherwise. Google told me in its Knowledge Graph to the right of the search results that Waitrose was in fact open.
Knowing that Google often gets things wrong in its Quick Answers and Knowledge Graph I checked the Waitrose website. Sure enough, it said “Thursday 01 Jan: CLOSED”.
If you look at the above screenshot of the opening times you will see that there are two tabs: Standard and Seasonal. Google obviously used the Standard tab for its Knowledge Graph.
I was at home working from my laptop but had I been out and about I would have used my mobile, so I checked what that would have shown me. Taking up nearly all of the screen was a map showing the supermarket’s location and the times 8:00 am – 9:00 pm. I had to scroll down to see the link to the Waitrose site so I might have been tempted to rely on what Google told me on the first screen. But I know better. Never trust Google’s Quick Answers or Knowledge Graph.
News and comments on search tools and electronic resources for research