One search engine bites the dust (Accoona) and another one is launched. I picked up details of Search (MSE360) via Phil Bradley’s blog posting and so far am very impressed with it. The home page is minimalist as is the norm these days and apart from the search box the only other obvious search option is a pull down list of countries. Hidden at the bottom of the page is an Options link that allows you to set safe search for images, change the default country, enable/disable WOT, and choose a different style sheet for your results. WOT is short for “Web of Trust” and is a community whose members exchange knowledge of websites. If a site has a bad reputation, WOT will warn you by inserting an icon next to the results. The colour of the icon ranges through shades of green, amber and red, red indicating sites about which you might want to exercise some caution. Hover over the icon and you can view the WOT ‘scorecard’.
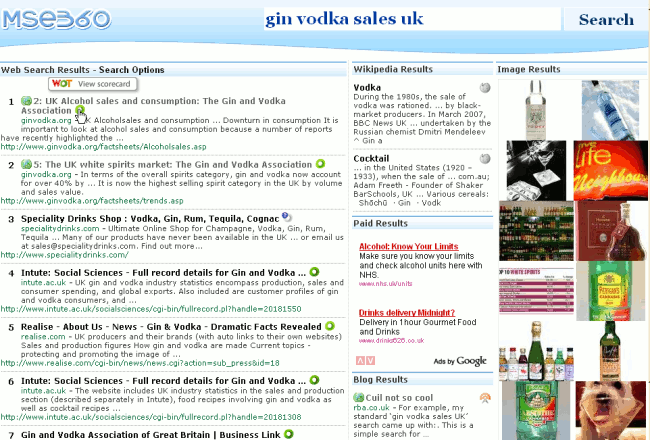
The results page is ‘three tiered’. The centre panel contains the usual web listings, and the default style has images on the left, and wikipedia and blog postings on the right. The layout can be changed by selecting a different stylesheet. I eventually decided to have both sidebars on the right hand side of the screen. There are the inevitable ads (Google) but these are in the sidebar and clearly labelled as Paid Results.
The quality of the results for my standard, basic test searches was excellent and compared favourably with Google. What did concern me initially was that there is no advanced search screen: I include site/domain and filetype commands in many of my searches and, for me, a search engine without them is a non-starter. After some experimentation, though, I discovered that that you can use the commands as part of your search strategy, for example
“car ownership” UK site:gov.uk filetype:pdf
I also found that you can use Boolean AND, OR and parentheses but not NOT (reminiscent of Yahoo!) . The minus sign can be used in a simple search if you want to exclude pages containing term but it does not seem to work when combined with Boolean operators.
Moving on to general issues, MSE30 stores no private data The only stored data are customization cookies on your own computer. Your IP is not kept, nor is any other identifiable information. To help combat spyware, they use an internal spyware alert program to provide warnings next to sites that may host spyware.
MSE360 say that they are still a test site so there are bound to be bugs, and no doubt some changes will be made to the interface. They say ” We’re not at a stage in which we can say we’re ready, but you still love hearing your feedback, good or bad”. My first impression is that they are very close to being ready and light years ahead of some of the appalling, over-hyped search engines that have been launched recently. I definitely recommend that you pay them a visit.