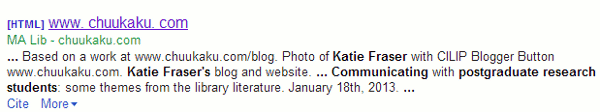The advanced Google workshop that I am running for UKeiG (How to make Google behave) has a new venue. It is still being held in Manchester but will now be in the 4th Floor Teaching Suite, Main Library, University of Manchester M13 9PP. The date remains unchanged (April 30th, 2013).
We shall be looking at what goes on “underneath the bonnet” and covering Google’s advanced commands and search options in detail. We’ll also be reviewing Google’s specialist tools including the Public Data Explorer, Scholar and many more. As usual with my workshops there will be time allocated for practical sessions so that you can try out the techniques for yourself. Further details and booking information are available on the UKeiG website at http://www.ukeig.org.uk/trainingevent/make-google-behave-techniques-better-results-karen-blakeman
Google has announced that as of July 1st 2013 Google Reader will be no more (A second spring of cleaning http://googleblog.blogspot.co.uk/2013/03/a-second-spring-of-cleaning.html). It comes as no surprise since I doubt Google receives very little revenue from it. On the other hand there must be a wealth of information on users’ reading habits and network connections, but obviously not enough. Google cites declining use as the reason.
To be honest I have never got on with Google Reader. I spend a lot of my time travelling on trains with dodgy wifi and erratic mobile broadband connections, so I download as much as possible to my desktop when I do have a connection. My favourite RSS reader at the moment is RSSOwl (http://www.rssowl.org/). I probably don’t use all of its features to the full but it does everything I need.
It is a desktop client with no web option or apps as far as I can see so will not suit many people. My second choice would probably be FeedReader (http://www.feedreader.com/). Originally only available as a desktop client it is now online. Number three on my list is Netvibes (http://www.netvibes.com/). This wouldn’t really be suitable for me as it is a web based service but it does offer some very neat alternative display options and has been used by many organisations to provide ‘start pages’ for their users.
To move your RSS feeds you now have to use the Google Takeout service (http://www.dataliberation.org/google/reader). There is no longer an option within Google Reader itself to export an OPML file. Takeout is going to be a problem for some people as it creates a zip file, which some organisations automatically block.
The demise of Google Reader is not a problem for me as I have never used it on a regular basis. What does worry me is that Feedburner (http://feedburner.google.com/) might be next for the chop. There has been virtually no development of the service for a couple of years and in July 2012 Adsense for feeds was discontinued, an indication Google does not view it as a revenue stream. I am now actively looking for Feedburner alternatives.
Google has put together a site showing how Google search works (http://www.google.com/insidesearch/howsearchworks/thestory/). The main page is a scrolling animated graphic that just gives you some elementary facts but there are links to more detailed information and videos on the main topics of crawling and indexing, the searching and ranking algorithms, fighting spam and Google’s general policies. They are a useful set of pages for anyone who does not already know the basics of how Google works, but if you are looking for something that tells you how to get sensible results from Google you’ll be disappointed. As Phil Bradley says:
“…. boils down to ‘we find some stuff, do magic to it, filter out the crap that our magic didn’t get and then give it to you.’ Yes folks, an entire site to say that. Wasted opportunity.”
Anyone who has attended one of my workshops knows that I ask the group to propose at the end of the session their top tips. These are the Canterbury group’s top 10 tips.
1. What’s going on?
Try and find out what’s going on behind the scenes and how the different search tools work. For example, Google and Google Scholar are quite different in the way they manage your search. Understanding how they operate means that you can adapt your search strategy accordingly and also manage your expectations; for example Google Scholar does not use the publishers’ meta data so author and date search are unreliable.
2. Personalisation and ‘unpersonalisation’
Google personalises your search based on past activity, who is in your social networks,and a whole host of other ‘stuff’. You can quickly ‘unpersonalise’ your results by using a separate browser window that does not use cookies or your web history as part of the search algorithm.
If you use Chrome as your browser, open what is called an incognito window. In the top right hand corner of your screen there is an icon with three lines. Click on it and from the drop down menu select New incognito window. Alternatively press the Ctrl Shift N keys on your keyboard
If you use Firefox, from the menu at the top of the screen select Tools followed by Start Private Browsing.
In Internet Explorer select Tools followed by InPrivate Browsing. If you cannot see InPrivate under Tools try looking under the Safety option.
3. Advanced search commands
Use Google advanced commands such as filetype: to focus on PDFs, presentations, spreadsheets containing data and site: to look for information on just one site or a range of sites such as UK government. Although the advanced search screen has boxes for you to fill in for the commands the file format or filetype option is limited. It does not include options for the newer Microsoft Office formats such as .pptx and xlsx. Use filetype: as part of your search strategy, for example:
nasa dark energy dark matter filetype:pptx
Google Scholar commands are more limited – see slide 28 of the presentation.
4. intext:
Google automatically looks for variations on your terms and sometimes omits words from your search if it thinks the number of results is too low. Prefixing a term with intext: tells Google that it must be included in your search and exactly as you have typed it in. For example:
UK public transport intext:biodiesel statistics
tells Google that biodiesel must be included in the search and exactly as typed in.
5. Reading Level
Use Reading level if Google is failing to return any research oriented documents for a query. Run the search and from the menu above the results select Search tools, All results and then from the drop menu Reading level. Options for switching between basic, intermediate and advanced reading levels should then appear just above the results. Google does not give much away as to how it calculates the reading level and it has nothing to do with the reading age that publishers assign to publications. It seems to involve an analysis of sentence structure, the length of sentences, the length of the document and whether scientific or industry specific terminology appears in the page.
6. Date options
In Google web search, use the date options in the menus at the top of the results page to restrict your results to information that has been published within the last hour, day, week, month, year or your own date range. Click on Search tools, then Any time and select an option. This works best with news, discussion boards, and blogs and web sites that use blogging software to generate pages but Google is getting better at identifying the correct date of a web page.
Google Scholar handles publication dates differently. On the results page you can select a date range from the menu on the left hand of the page. Alternatively, you can run a Google advanced search and enter your publication years. However, Google Scholar looks for publication years in the area of the document where the date is most likely to be. As a result it may identify a page number or part of an author’s address as a year!
7. Google Scholar alerts
To be used with caution as the searches periodically stop without warning, and so have to be set up again, and they sometimes include documents that are several years old. Whatever your search you can set up an alert by selecting Create alert from the menu on the left hand side of the results page.
If the author has created a profile on Google Scholar, from their profile page you can follow new articles and/or new citations for that author. From past experience I warn you that this is not entirely reliable.
8. Metrics – top publications Although it claims to search all scholarly literature Google Scholar does not always cover all of the key journals in a subject area. There is no complete source list but there is a top publications for subjects and languages under the ‘Metrics’ link in the upper right hand corner of the Scholar home page.
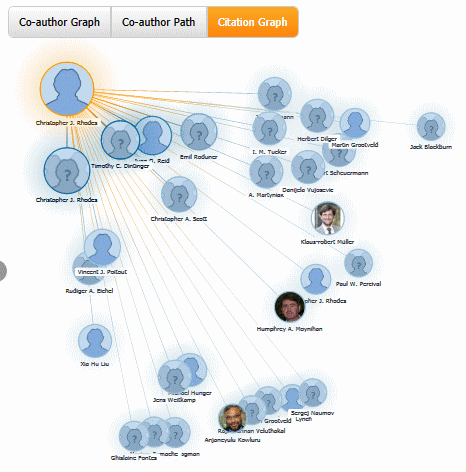
9. Microsoft Academic Search – visualisations
Microsoft Academic Search (http://academic.research.microsoft.com/) is a direct competitor to Google Scholar. The site is sometimes slow to load and it often assigns authors to the wrong institution. Nevertheless, the visualisations such as the co-author and citation maps can be useful in identifying who else is working in a particular area of research. The visualisations can be accessed by clicking on the Citation Graph image to the left of the search results or author profile.
Author Citation Graph
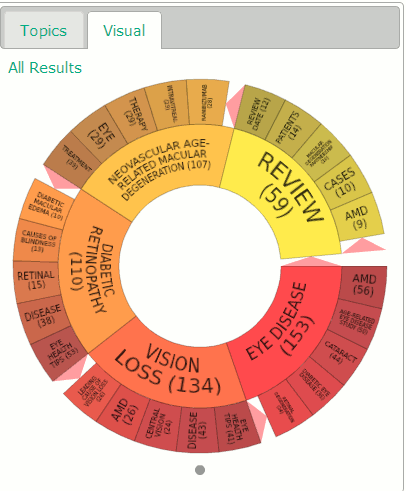
10. Mednar visual Deep Web Technologies has developed in conjunction with various institutions a number of science and research specific portals, some of which are publicly available. The sources that they cover are different but they all have similar search and display options. Results are automatically ranked by relevance but this can be changed to date, title or author. In addition to the standard relevance ranked list of results the portals create clusters of topics on the left hand side of the screen. The topics include broad subject headings, authors, publications, publishers, and year of publication and are a useful tool for narrowing down a search. Some of the portals, such as Mednar (http://mednar.com/), offer a clickable ‘visual’ of topics and sub-topics.
I am running three workshops in April on business information and search. All three have a practical element so that you can try out resources and techniques for yourself.
Introduction to Business Research
This is being organised by TFPL and will be held in London on Thursday, 18th April. This course provides an introduction to many areas of business research including statistics, official company information, market information, biographical information and news sources. It will cover explanations of the jargon and terminology, regulatory issues, assessing the quality of information, primary and secondary sources. Further information is available on the TFPL web site at http://www.tfpl.com/services/coursedesc.cfm?id=TR1116&pageid=-9&cs1=&cs2=f
Business information: key web resources
This is also being organised by TFPL in London and is being held on Friday, 19th April. This workshop looks in more detail at the resources that are available for different types of information, alerting services and free vs. fee. It also covers search strategies for tracking down industry, market and corporate reports. Further information is available at http://www.tfpl.com/services/coursedesc.cfm?id=TR945&pageid=-9&cs1=&cs2=f
Make Google behave: techniques for better results
This is a very popular workshop and is being organised by UKeiG. It is being held in Manchester on Tuesday, 30th April.
Topics include:
How Google works
Recent developments and their impact on search results
How Google personalises your results and can you stop it?
How to use existing and new features to focus your search and control Google
How and when to use Google’s specialist tools and databases
What Google is good at and when you should consider alternatives
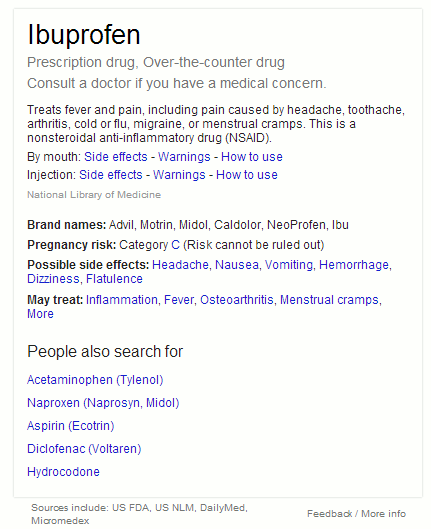
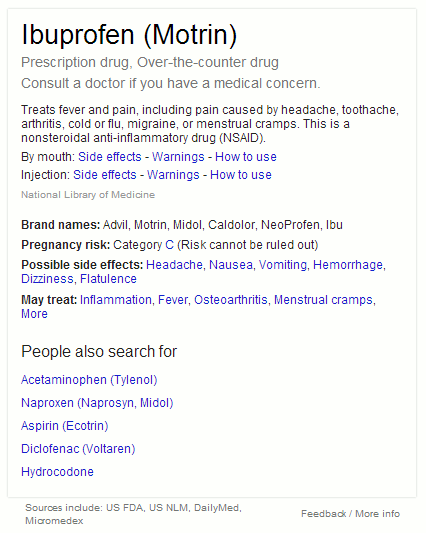
When I search on ibuprofen Google now gives me some key facts on the drug in a box to the right of the standard web results. The information includes indications for use, side effects, brand names, contraindications and other drugs that people also searched for. The sources it uses are the National Library of Medicine, US FDA, DailyMed and and Micromedex.
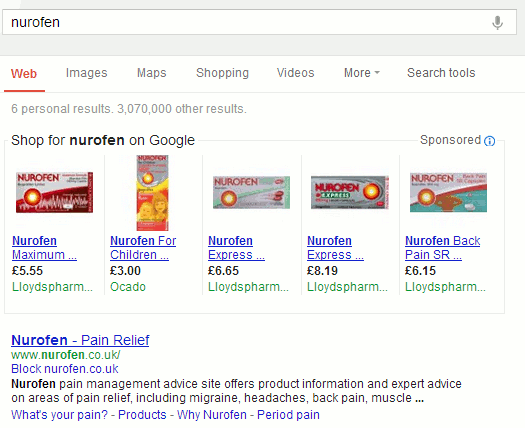
Ibuprofen is the generic name for this painkiller and is one of the names under which it is sold in the UK and many other countries. Searching on the brand name Nurofen, which is not available in the US, brings up web search results with shopping options at the top. There is no knowledge graph this time.
I played around with a few other brand names and found that if it is on sale in the US, for example Motrin, Google is able to identify the active ingredient.
So Google’s new medicine search is US-centric: US brand names and US sources of information. It will be interesting to see if and how they roll it out to other countries. Meanwhile, for those of in the UK NHS Choices provides better and more detailed information on medicines at http://www.nhs.uk/medicine-guides/, and if you are interested in a drug’s physical or chemical properties Chemspider (http://www.chemspider.com/) is a good starting point.
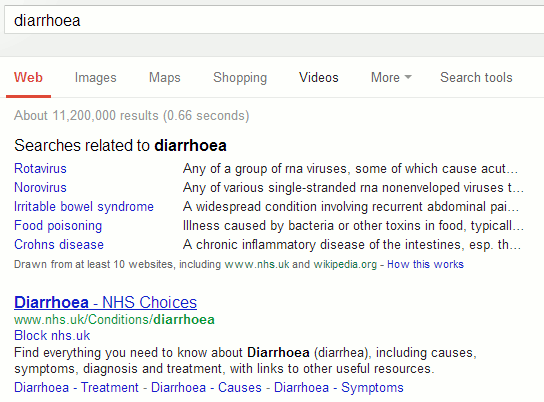
Already appearing in UK Google results is the related medical conditions feature. Type in a symptom and Google lists possible related conditions at the top of the page.
If you are using Google.co.uk or are based in the UK clicking on any of the conditions in the list brings up content that is UK focused. It will be interesting to see if they do the same with the medicines knowledge graph.
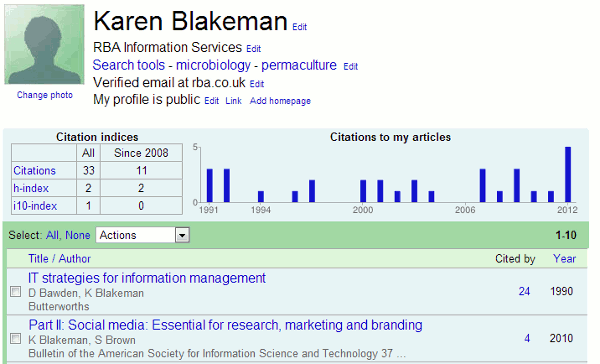
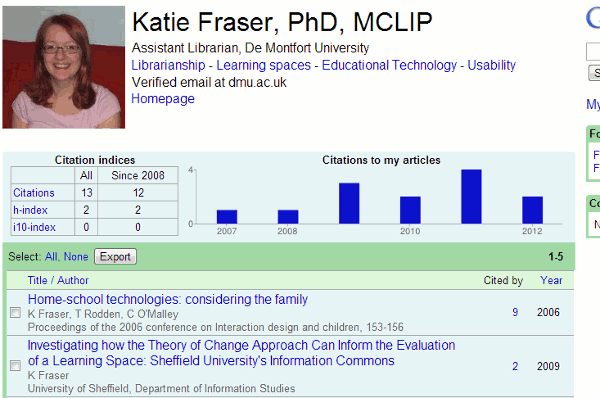
Eight months after setting up my Google Scholar author profile and “claiming” my papers I have received my first alert. If you only use Google Scholar (http://scholar.google.com/) to search for papers you may not be aware that if you have published papers you can set up a Google Scholar author profile and add those papers to your profile. Google then creates a page showing a graph of when and how often your papers were cited and generates an H-index and i10-index for you.
This only covers the papers that Google Scholar has in its database and there are serious gaps in its coverage for some sectors. On the other hand, it does sometimes include articles, web sites and blog postings that are not peer reviewed in the conventional way. This can be a good thing because it may pick up some very useful grey literature. It can be a bad thing because it is possible to fool Scholar into adding a paper of dubious quality by mimicking the structure of an academic paper – title and author names in large font, affiliation, abstract, keywords, list of references etc.
Another feature of Scholar is that you can create alerts for keyword searches, new papers by an author or new citations to their articles. Needless to say I have set up alerts on my own name! Sadly, until last week I had received nothing so had to assume that no-one was interested in or citing my papers. Or perhaps the alerts do not work? Whatever the reason, I was delighted that at last someone had mentioned me in some way in an article. Clicking through to the item, though, led me to Katie Fraser’s blog and “Communicating with postgraduate research students: some themes from the library literature” (http://www.chuukaku.com/blog/2013/01/communication-with-pgr.html). Was I mentioned or cited in the posting? No, but my own blog was listed in her blogroll to the left of the article.
Having got over the disappointment I turned my attention to working out why Scholar had picked up this particular post. Why wasn’t I receiving alerts every time Katie updated her blog? The answer appears to be at the end of the posting in question: Katie has provided a list of references.
Another factor, I thought, might be that Katie has an author profile and claimed her papers but I could not see it anywhere in her profile.
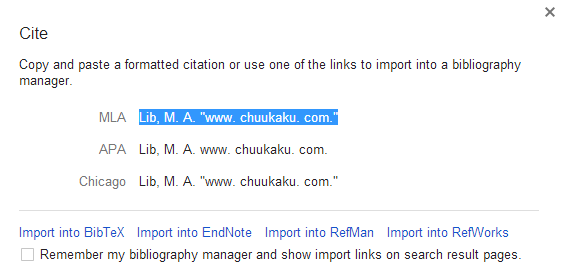
On further investigation, and unfortunately for Katie, Google Scholar is unaware that she is the author of this article. It appears that it is someone called MA Lib.
This was confirmed when I clicked on the ‘Cite’ option. This presents you with formatted citations that you can cut and paste into an article or import into a bibliography manager. The author is definitely MA Lib.
Google Scholar has failed to recognise Katie Fraser as the author and has decided that the MA Lib link in the side menu of her blog is a person’s name. There are many similar examples and it is well known that Scholar is unreliable when it comes to identifying authors. Peter Jacso has written several articles detailing Scholar’s shortcomings in this area. (1, 2, 3, 4). Many of his articles are available as pre-prints (5)
What this means for Katie is that although Google Scholar believes her blog posting (6) is worthy of inclusion in its database it is not listed in her author profile and does not contribute towards her h or i10-index. And in case you are wondering, yes I have appended references to this posting to see if Google regards it as scholarly literature and adds it to the Scholar database
Update: Katie Fraser has now “claimed” the posting for her profile but the Google Scholar database has not yet been updated to reflect this.
References
(1) Jacsó, Péter. “Metadata mega mess in Google Scholar.” Online Information Review 34.1 (2010): 175-191.
(2) Jacsó, Péter. Newswire Analysis: Google Scholar’s Ghost Authors, Lost Authors, and Other Problems [Online] 24 September 2009 [Accessed 4 February 2013.] http://www.libraryjournal.com/article/CA6698580.html
(3) Jacsó, Péter. “Google Scholar Author Citation Tracker: is it too little, too late? “Online Information Review 36.1 (2012): 126-141.
(4) Jacsó, Péter. “Using Google Scholar for journal impact factors and the h-index in nationwide publishing assessments in academia–siren songs and air-raid sirens.” Online Information Review 36.3 (2012): 462-478.
One of my Twitter network complained today that when they went to run a Google search a Google+ reminder for someone’s birthday popped up in top right hand corner. Google did the same to me prompting me to wish them a Happy Birthday. Does that remind you of another social network beginning with F? Yes, we were both signed in to our Google accounts and I have confessed on several occasions that I have sold my soul to Google. I have even gone as far as to sync all my data between my devices and my Google dashboard via Chrome. I made that decision knowing how much information about me that would give Google but I decided it would be worth doing. I can access my maps, bookmarks, searches etc. when I’m on the move and using my Android smartphone; and if my laptop dies all my Google and web browsing stuff can be quickly restored to a new machine.
I still have another Google account that predates even Gmail but on the few occasions when I use it Google doesn’t so much suggest rather than demand that I upgrade to Google+. It requires a lot of effort, ingenuity and many clicks to say “NO!” Many of Google’s services and search features now require you to have an account and by default it may soon have to be a Google+ account. A reminder that someone in your Google+ circle has a birthday may seem a minor issue but as my Twitter correspondent said “function creep”. And there’s been a lot of that going on in Google search recently.
Just when you thought you had sussed out the additional search options on Google’s results page Google decides to move them. Instead of appearing to the left of your results page the menu has been moved to the top, leaving a blank space where the old menus used to be.
There are the usual options such as images, maps, shopping and videos and clicking on More reveals a drop down menu for News, Books, Places, Blogs etc.
It begins to get confusing when you click on Search tools and an extra row of options appears.
It is not obvious what the “The Web” does but clicking on it gives you two options. “The Web” is the default and I assume that to be the whole of the world because the second option for me is the UK. Presumably for those of you in other countries it will be your own country. The “Any time” option gives you the various time periods and custom time period by which you can limit your search. “Reading, UK” is my physical location and some results are personalised using that location. The location can be changed to another town or the country as a whole, as with the previous side bar menus. It is not clear what “All results” does but again clicking on it reveals the final set of search options including the all important Verbatim.
As with previous side bar menus, the second level options change depending on which type of resource you are searching. For example, if you click on Search tools in Images there are links that take you to options that include size, colour and type.
This change looks as though it is here to stay as most people in the UK are now seeing it and several of the country versions of Google I’ve looked at are also displaying it. All the old options are still there but it requires extra clicks to get to the same place and I sometimes forget what each link has underneath it. So those of you who, like me, run training sessions expect to spend the next few weeks updating your slides and training materials.
Google search is about to get even more personal – possibly. If you are signed in to your Google account and search Google.com, Google includes and highlights content from people in your networks. This has been available for some time but a couple of months ago Google launched a field trial that added your Gmail to the search mix, and a few days ago they added documents from Drive. You have to request to be added to the field trial and it only works on Google.com. If you are interested in trying it out you can signup at https://www.google.com/experimental/gmailfieldtrial.
Above your results Google.com tells you how many personal and other results have been found. A head and shoulders icon next to a result indicates that it is from someone in one of your networks. Click on the number of personal results to see just those. Across to the right there are a head and shoulders and world icons. If you want to hide the personal results click on the world icon. If you have searched on a person or an organisation their Google+ profile, if they have one, is shown to the right of the screen. Above this, any messages or documents in your Gmail and Drive that match your search are displayed.
I have mixed feelings about this. At first I was very much against the integration of personal posts and data with general search. If I want to search Google+ I’ll do it within Google+, and similarly I go into Gmail if I want to search my email. However, I would not routinely do that for research projects and during this field trial I have sometimes found useful information in my Google+ circles, giving me a very different view of the topic/person/organisation I am investigating. The question then is can I pass this on to a client or include it in a report? The answer is not straightforward. If the Google+ posting has been made public and not restricted to a circle then yes. Otherwise I would have to obtain the person’s permission to use it or pass it on. With Gmail I would have to obtain permission from all the parties concerned and I would also need to check the ownership of any documents identified within my Drive.
I can clearly see and understand the difference between public and private search results as I am sure all information professionals and many researchers can, but I do wonder about other Google users. “It’s come up in a Google search so I’m free to use it as I want”. It could be argued that you shouldn’t put anything up on Google+ unless you don’t mind it going public, even if you have restricted it to a small circle of contacts but email should remain private and be kept out of general search results. I can see legal actions looming!
This is a limited field trial, though, so not everyone who uses Google.com is seeing the Gmail and Drive results yet. If you do take part in the trial and have any concerns about how it works and potential privacy issues, there are feedback links next to the Gmail and Drive results. Use them!
News and comments on search tools and electronic resources for research